Modern AI and HPC workloads place extraordinary demands on the underlying network infrastructure. And as network engineers, we are often pulled into conversations about GPU clusters, maybe without a clear map of the terrain.
Three terms come up constantly: scale-out, scale-up, and scale-across networking.
They describe fundamentally different network constraints and requirements. Here is a brief and simple explanation of each.
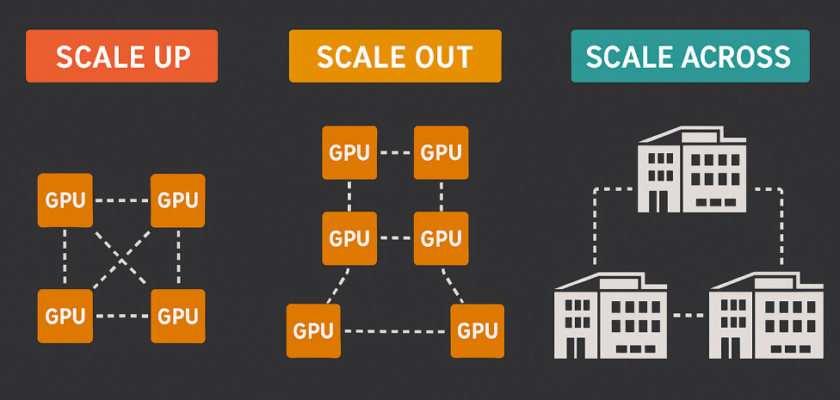
Scale-Out: The East-West Fabric
Scale-out refers to expanding compute capacity by adding more nodes to a cluster. In networking terms, this is the domain you already know well: a typical Clos fabric. But it can also be a different topology for larger systems, high bandwidth, and parallel traffic patterns that are predominantly east-west between compute nodes.
In AI training, scale-out is what happens when, for example, a model is too large or too slow to be trained on a single server. You distribute the workload across dozens, hundreds, or thousands of compute nodes. And the network must support efficient collective communication operations (AllReduce, AllGather, etc.) across the entire cluster or pod. Technologies like InfiniBand NDR/XDR or 400/800Gb Ethernet with RoCEv2 are the common choices here. Proprietary technologies like HPE/Cray Slingshot are also quite common in the top-500 HPC centres, or MRC (Multipath Reliable Connection) in large GenAI clusters. Latency sensitivity is high, and any congestion or imbalance in the fabric directly impacts training or inference throughput.
This is the most familiar quadrant for network engineers: it looks like a data centre fabric, just pushed to extreme bandwidth and latency requirements.
For very large or specific clusters, we may also have more than one scale-out network; for example, one for the GPU-to-GPU communications and another one for GPU-to-storage communications.
Scale-Up: Within the Rack
Scale-up refers to maximising compute density within a single rack or cabinet by packing more GPUs together and connecting them at very high speed over short distances. This is the realm of proprietary high-speed interconnects like NVLink and NVSwitch (NVIDIA), AMD’s Infinity Fabric, and the emerging open standard UALink; an industry consortium effort to provide a vendor-neutral, high-bandwidth, and ultra-low-latency interconnect for accelerator-to-accelerator communication within a rack.
From a network engineering perspective, scale-up is largely transparent: it happens behind the NICs, within the rack, and the external fabric doesn’t see it directly. However, it does shape what we see at the top-of-rack switch. A tightly coupled group of accelerators handling collective operations internally puts enormous aggregated bandwidth demands on the uplinks, which is why modern AI servers often present 4, 8, or more high-speed NICs per host.
Understanding scale-up helps you appreciate why rack power densities have exploded. We are now starting to talk about 1MW per rack in some near-future deployments. And why the physical and electrical constraints of the rack are as much a design constraint as the network topology above it.
Scale-Across: Connecting Clusters or AI factories
Scale-across is the newest and perhaps least familiar concept. It refers to extending GPU-level communication across multiple clusters or sites. It effectively treats geographically or administratively separate compute clusters as a single logical system.
This is where networking gets interesting again. Scale-across requires low-latency and high-bandwidth interconnects between data centres or HPC sites. The network must now carry RDMA traffic across longer distances, maintain minimal jitter, and maintain the tight synchronization that distributed training requires. Technologies like Ultra Ethernet, RoCEv2 over long-haul links, and specialised optical interconnects are being explored for this domain.
At large HPC centres, scale-across is increasingly relevant as AI workloads grow beyond what any single facility can host. Stitching together multiple compute sites puts the network engineer firmly in the critical path.
Putting It Together
| Dimension | Scope | Key Network advantages/challenges |
| Scale-Up | Within a rack/cabinet | Ultra-low-latency and very high-bandwidth between the local GPUs/nodes. No or very limited scalability. |
| Scale-Out | Within a cluster | Latency must stay under control. High bandwidth is needed with possible big traffic spikes (lot of parallel communications) for training. Lower bandwidth is required for inference, but also a lower latency. Large-scale deployments. |
| Scale-Across | Between clusters/sites, DCI | Long-haul RDMA, latency is also important here, for synchronization, and controlled Jitter. |
Two or all three of these axes are often deployed simultaneously in large AI infrastructure projects. AI workloads need both high-bandwidth between many nodes (scale-out) and ultra-low latency (scale-up). A well-designed network strategy needs to address each layer; even if scale-up is mostly handled by the server vendor, it shapes the assumptions you carry into the fabric design above it.
For network engineers stepping into the AI infrastructure space, mapping these terms to familiar concepts makes the conversations much easier. This is why I deliberately kept this post simple and at a high-level.