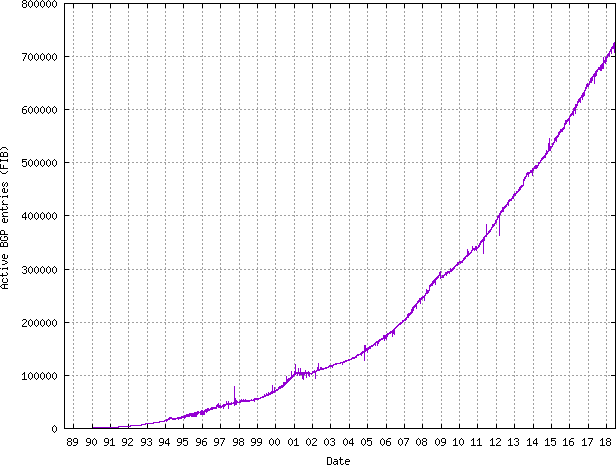
The IPv4 full BGP table size is around 725000 prefixes now. This may cause problems for companies that do not have the resources to update or upgrade their edge routers.
But, except for Internet transit providers, who really need to get the full IPv4 BGP table today? And what are the alternatives?
Let’s see that in detail with some use cases.
No BGP
First example, if my company only needs Internet access, without providing any service, I do not need BGP at all. A default route, pointing to my ISP, is enough.
If I want more redundancy, then I can take two different ISPs. But here also, BGP is not always needed.
>If I want to make some load-sharing between the two links, I can do it with NAT, for example: part of my outgoing traffic towards the Internet could be “NATed” with my ISP-A and another part with ISP-B. The return traffic will come back the same way.
Now, what if my company has on-site servers that need to be reachable from the Internet? Again, with a single ISP, there is no problem; I can do this with NAT too.
But with two or more uplinks, this is more complex. A smart combination of different DNS entries and NAT/PAT can be used. Or a load-balancing device with the different uplinks connected to it, too. Or, we can also use dynamic DNS and NAT/PAT if the different ISP provides only dynamic IP addresses.
>But here, we reach the limit of an acceptable design: the redundancy may not always be guaranteed if one ISP goes down. For instance, some parts of the Internet could reach my servers and some parts not. And finally, the troubleshooting of a solution like this may be quite difficult.
Multi-homed BGP with default-routes
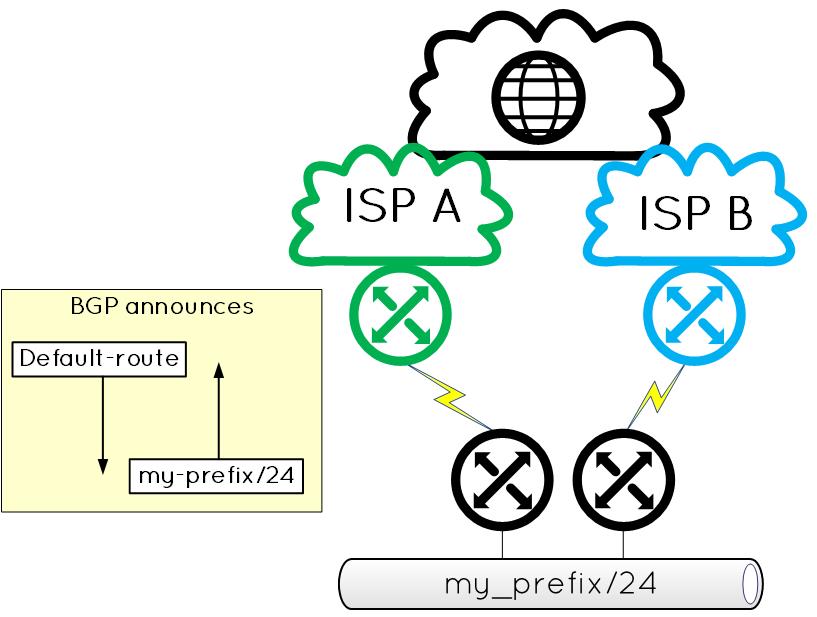
In the case my company has a public IP subnet, provider-independent or provided by one of the two ISPs, and needs at least two different ISPs to achieve redundancy, the best way is to use BGP. But, nothing complex here: my company announces its IP prefix to both ISPs, and both ISPs announce a default route to my company’s edge routers.
High-Level Drawing
Failures scenarios
In this situation, if the ISP-A fails or the link to ISP-A fails, my company prefix is not announced anymore to them. Then, the Internet traffic from or to “my_prefix” goes through ISP B. This is a very common solution to achieve redundancy.
The problem with this solution is the lack of control over where the traffic from and to the Internet will go. In fact, the egress traffic from “my_prefix” to the Internet will go through only one ISP, except if you use “bgp bestpath as-path multipath-relax” with Cisco devices or an equivalent feature. I explained this feature in details into this post. And the ingress traffic path will depend on both ISPs’ traffic engineering, traffic policies, and connectivity to the rest of the Internet.
For example, if ISP-A is a tier-1, with excellent connectivity to the world, and ISP-B is a very local services provider with only one upstream provider, there is a good chance that most of the ingress traffic comes from ISP-A. Unless the clients of my company are all connected to ISP-B.
ISPs choice
So in this case, the choice of the different ISPs is crucial. Not just the price but also the connectivity to my potential customers or partners, as well as the connectivity of other ISPs. Imagine if the ISP-B has only one upstream provider towards the Internet, and this is ISP-A …
Of course, we can influence the ingress traffic with different BGP attributes, like AS-path prepending for example, MED in the case of multiple links to the same ISP, or with egress communities tagging if the upstream provider is providing traffic-engineering possibilities. Other solutions could be announcing more specific prefixes to one or the other ISP (de-aggregation). Or, of course, with a combination of multiple of these parameters
But we still have almost no control over the egress traffic. The options here are one ISP active / one ISP backup, or both active with a load-sharing method explained here.
Multi-homed BGP with full-routes
To have more control over the egress traffic, the default choice for many years is to build a BGP multi-homed network and get the full BGP routing tables from the different upstream providers. Like this, we receive the entire routing table into the routers we control, and we can build our own traffic policy for the egress traffic.
The problem: BGP tables are growing
The problem with full BGP tables is that the IPv4 and IPv6 BGP table sizes are constantly increasing, and this has a significant impact on your routers.
The IPv4 space fragmentation is the direct repercussion of the IPv4 address exhaustion: we see more and more /24 subnets in the BGP tables.
>The IPv6 table is growing more “naturally” – around 53000 at the time I wrote this article – following the deployment of new IPv6 prefixes across the world.
The problem of the limited FIB/RIB capacity and growing BGP table size is not new; multiple outages were reported in 2008, when the BGP table size crossed the 256K limit, and again in 2014 when the 512K entries limit was exceeded. A good article here describes the problems experienced in 2014.
The 768K limit
In summary, the BGP advertisements received by a router are processed and inserted into a table called the Forwarding Information Table (FIB). This FIB has a maximum limit of entries, determined by many factors like the amount of memory, the hardware (ASICs), and sometimes also the software. And not all vendors support dynamic allocation of FIB entries between route-types (IPv4, IPv6, MPLS). For example, a router may support 1 million routes in total, but it is limited to only 756K prefixes for IPv4 and 256K for IPv6 prefixes.
As the IPv4 table is very close to 756K, there is a good chance that the problems experienced in 2008 and 2014 will recur very soon.
Moreover, if we look at the extremely slow deployment of IPv6 across the world, the partitioning of the IPv4 table may increase again and again. At the end, the BGP IPv4 full-route solution explained above may be a very expensive solution. And how will you, as a network engineer or IT manager, justify the cost of multiple upgrades of your edge routers, just because the Internet is growing?
Multi-homed BGP with partial-routes:
The good compromise
So, the question is, do we really need all the IPv4 Internet prefixes? Do we need to always use the shortest AS-path to reach one destination at the other side of the world? For many companies, the answer is clearly no!
A good compromise between the most important routes and the default route seems the most scalable solution. I personally implemented this solution for a customer a few months ago. I will explain it below in detail.
Customer use-case
My customer wanted to have good global connectivity. An excellent local connectivity. And not spend too much money on the edge routers.
My solution was this one:
- Take two links to tier-1 IP transit providers, both with excellent global connectivity
- Take two other links to two national ISPs, those with the most residential and business customers, to have the best connectivity within the country.
- Filter the prefixes and accept only the most interesting routes received by all of them, plus the default routes from the two tier-1 ISPs.
National connectivity
From the two national providers, no need for default and upstream routes. I kept only the prefixes of the ISP and its customers.
- One of the two is using community tagging to designate where the prefix comes from (upstream, customer, himself), so for this one, the filtering was easy.
- For the second one, some reverse lookup on the RIPE database gave me all the needed information to build a good AS filter. Yes, I agree, this is a static filter for the moment, but I am looking for a more dynamic solution.
Global connectivity
For the two tier-1 ISP, we made some experiments with the customer. And first decided to keep the provider’s own prefixes, plus the first AS behind. In addition to that, we also keep some specific AS in relation to the business of this customer. A simple BGP AS reg-exp filter is used for this.
The results
The results were excellent! The IPv4 routing tables were composed of this:
- Between 2’000 and 5’000 IPv4 prefixes for the national providers.
- Around 125’000 IPv4 prefixes for the first tier-1.
- Around 250’000 IPv4 prefixes for the second tier-1.
So, a total of less than 400’000 IPv4 prefixes in total.
This is still a relatively high number, but we can still filter more prefixes depending on the customer’s needs. We just started a long-term traffic analysis to fine-tune the AS filters.
The default routes
And about the prefixes we do not have in the routing table?
For these, we asked the two tier-1 ISPs to also provide us a default route. And we load-share the traffic between the two with the “bgp bestpath as-path multipath-relax“. This feature is explained on this post.
In summary
- Regional egress traffic is going to two regional ISPs.
- Global egress traffic to the shortest AS-path tier-1 ISP.
- The rest of the egress traffic is load-shared between the two Tier-1 ISPs.
- The ingress traffic comes from the shortest AS-path of the 4 ISPs.
- If any of the ISPs go down, the redundancy is assured.
- We reduced the IPv4 table size by nearly 50%, and we can do even better.
One last important point
When a router receives the full BGP table from an upstream, after the establishment or re-establishment of the session (after a hard reset), even if the router filters more than 50% of the full BGP table, the entire table is still processed by our router (all the BGP update messages) and THEN filtered. This must be considered when you do the sizing of the router.
ORF (outbound route-filtering) could be a good solution to solve this. But I don’t know if any ISP agrees to use this with one of their customers.
The other solutions could be to ask your upstream provider to announce only what you need. But this requires administrative work and delays when we need to change a filter.
Conclusion
With the actual growth of the BGP IPv4 routing table, partial routing is an excellent solution. More intelligent and sophisticated solutions in this area are also coming. For example, an SDN controller can make real-time analysis of the prefixes received, and dynamically inject only the most interesting into the edge routers.